














Azure Data FactoryのデータフローでJSONを読み込んでテーブルにインポートする(Array of documents)
前提
- SQL database作成済み
- データセット作成済み
- Azure BLOB ストレージ作成済み
データフロー作成
「データフロー」にカーソルを合わせて右クリックし「新しいデータフロー」をクリックします。

「ソースの追加」にカーソルを合わせてクリックします。

「ソースの種類」を「インライン」にして「インラインデータセットの種類」を「JSON」に設定します。

「リンクサービス」をあらかじめ作成しているAzure BLOB ストレージにします。

「ソースのオプション」タブをクリックし、ファイルパスを「参照」から入力します。
「ドキュメントのフォーム」は今回のemp.jsonファイル形式に合わせて「Array of documents」にします。


emp.json
[
{
"id": "1",
"name": "takahashi",
"age": "20"
},
{
"id": "2",
"name": "yamada",
"age": "30"
},
{
"id": "3",
"name": "wada",
"age": "40"
}
]
「データフロー」のソース右下にある「+」をクリック、「シンク」を選択して保存します。

シンクの設定をします。
着信ストリーム:source1
データセット:AzureSqlTable3
AzureSqlTable3のDDL(dbo.empテーブル)です。
CREATE TABLE [dbo].[emp](
[id] [int] NOT NULL,
[name] [nvarchar](50) NOT NULL,
日付未入力 [int] NOT NULL,
CONSTRAINT PK_Student PRIMARY KEY ([id])
) ON [PRIMARY];

これでデータフロー作成完了です。

パイプライン作成
作成した「データフロー」をパイプラインにD&Dします。

デバッグ
「検証」でエラーが出なければ「デバッグ」を押して確認します。

dbo.empテーブルを確認します。
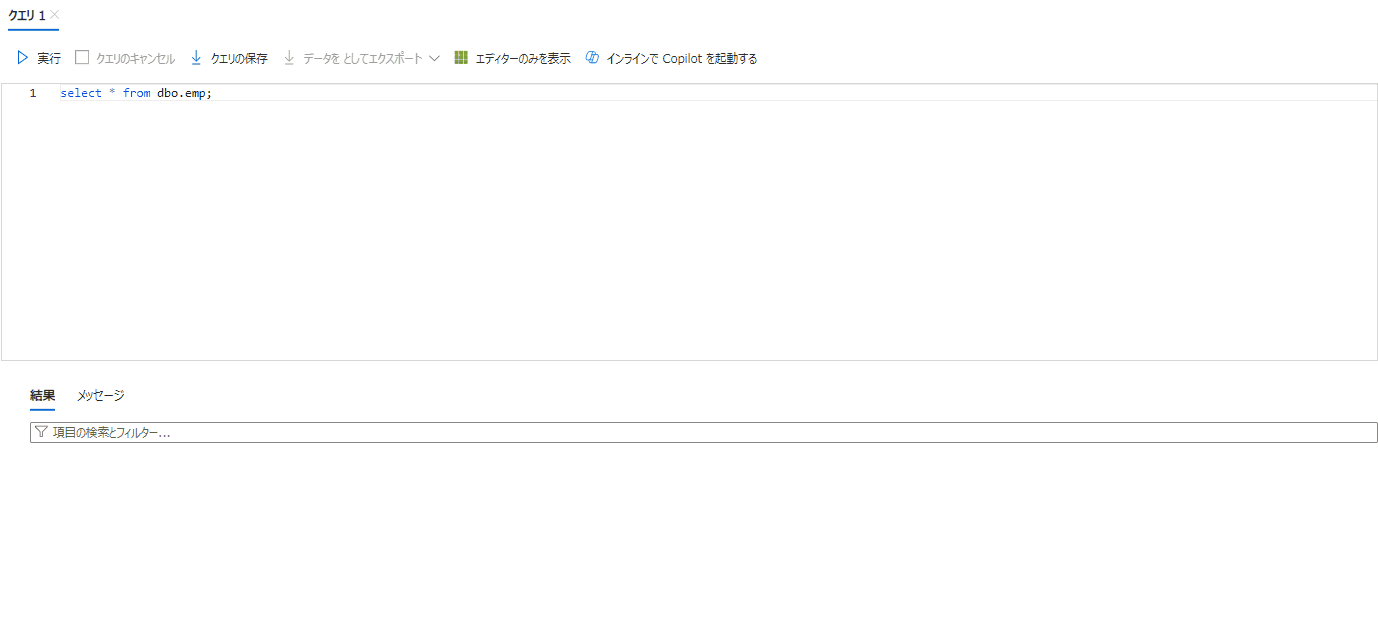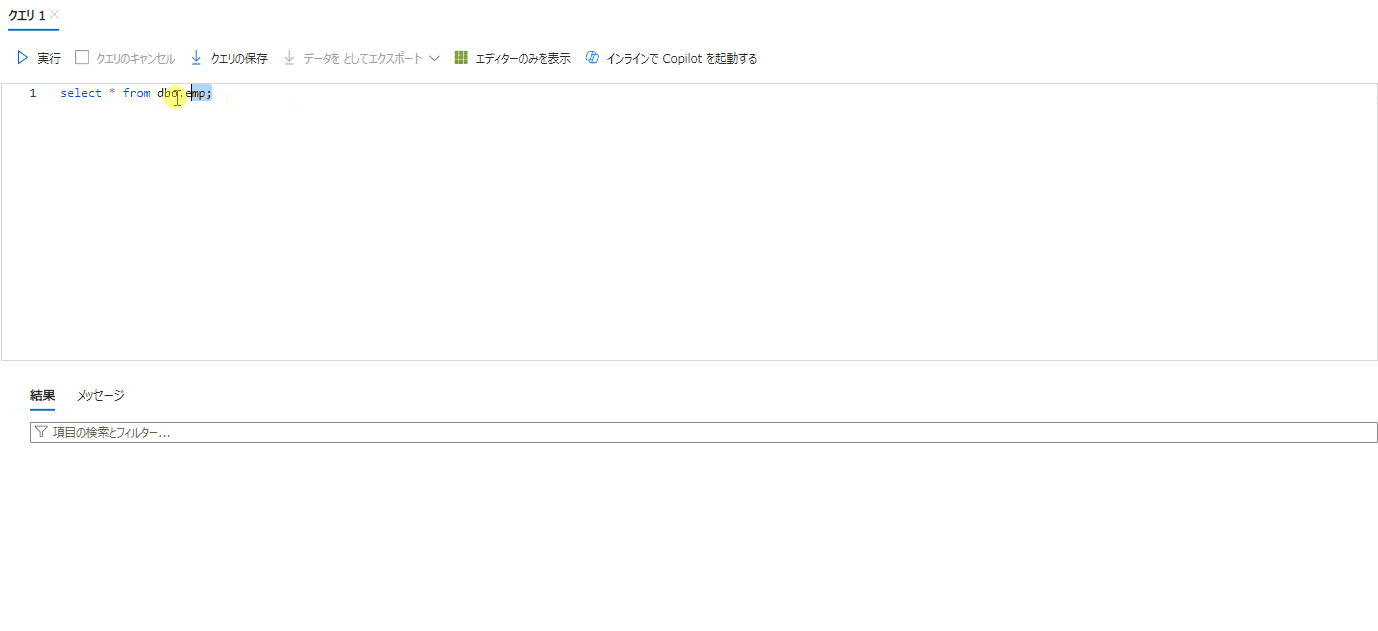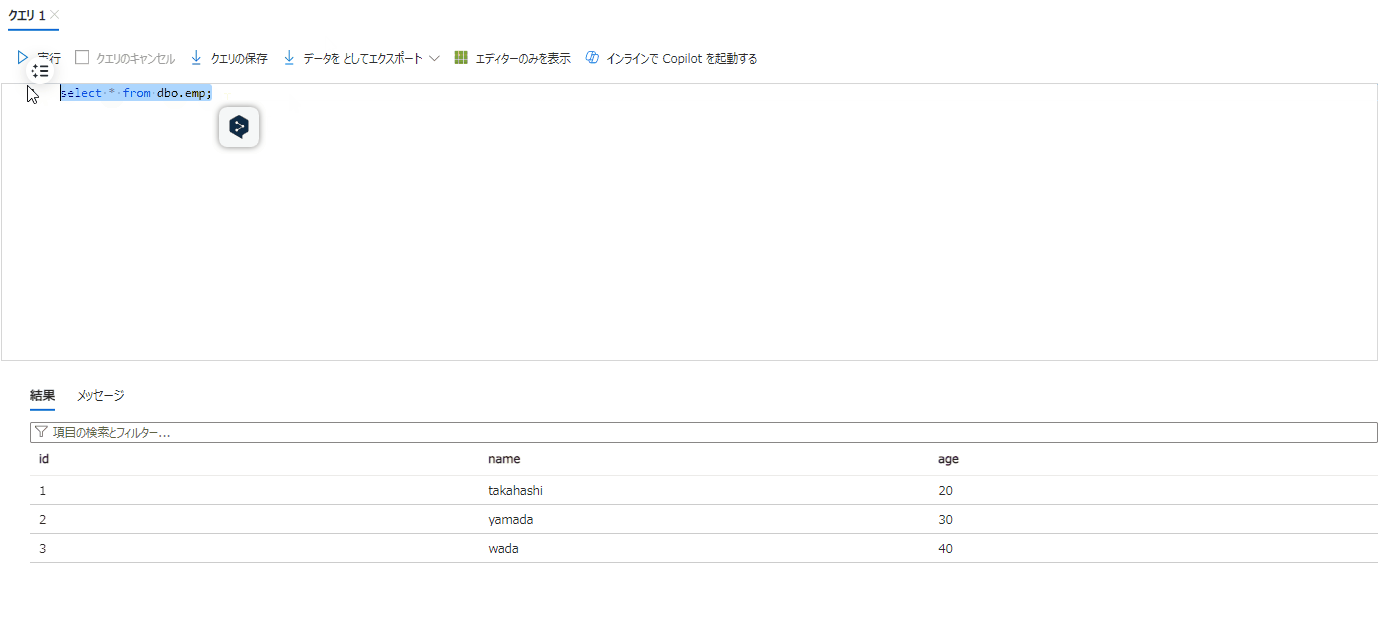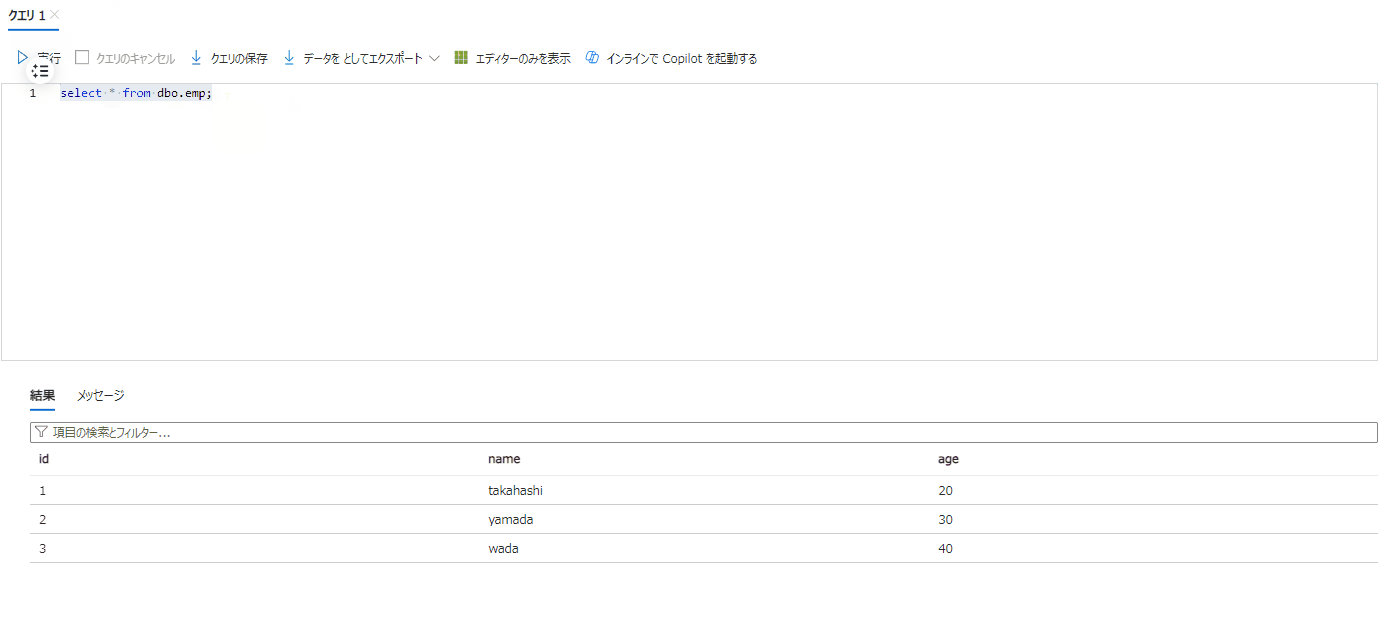
3件レコードが追加されていることが確認できます。
Document per line
Document per lineの例です。
emp.json
{"id":"1","name":"takahashi","age":"20"}
{"id":"2","name":"yamada","age":"30"}
{"id":"3","name":"wada","age":"40"}

KHI入社して退社。今はCONFRAGEで正社員です。関西で140-170/80~120万から受け付けております^^
得意技はJS(ES20xx),Java,AWSの大体のリソースです
コメントはやさしくお願いいたします^^
座右の銘は、「狭き門より入れ」「願わくは、我に七難八苦を与えたまえ」です^^
